You interact with AI every day—through chatbots, translation apps, or even your phone’s autocomplete. The "brain" behind these tools is a Large Language Model (LLM). But how do you actually build one?
It turns out the process isn’t so different from how a person learns: first a broad education, then specialized training, and finally a check to make sure the student can apply knowledge well. For LLMs, this journey happens in three stages:
- Building the model architecture and preparing the data
- Pretraining on massive, unlabeled text
- Finetuning for specialized tasks
Let’s break down each stage.
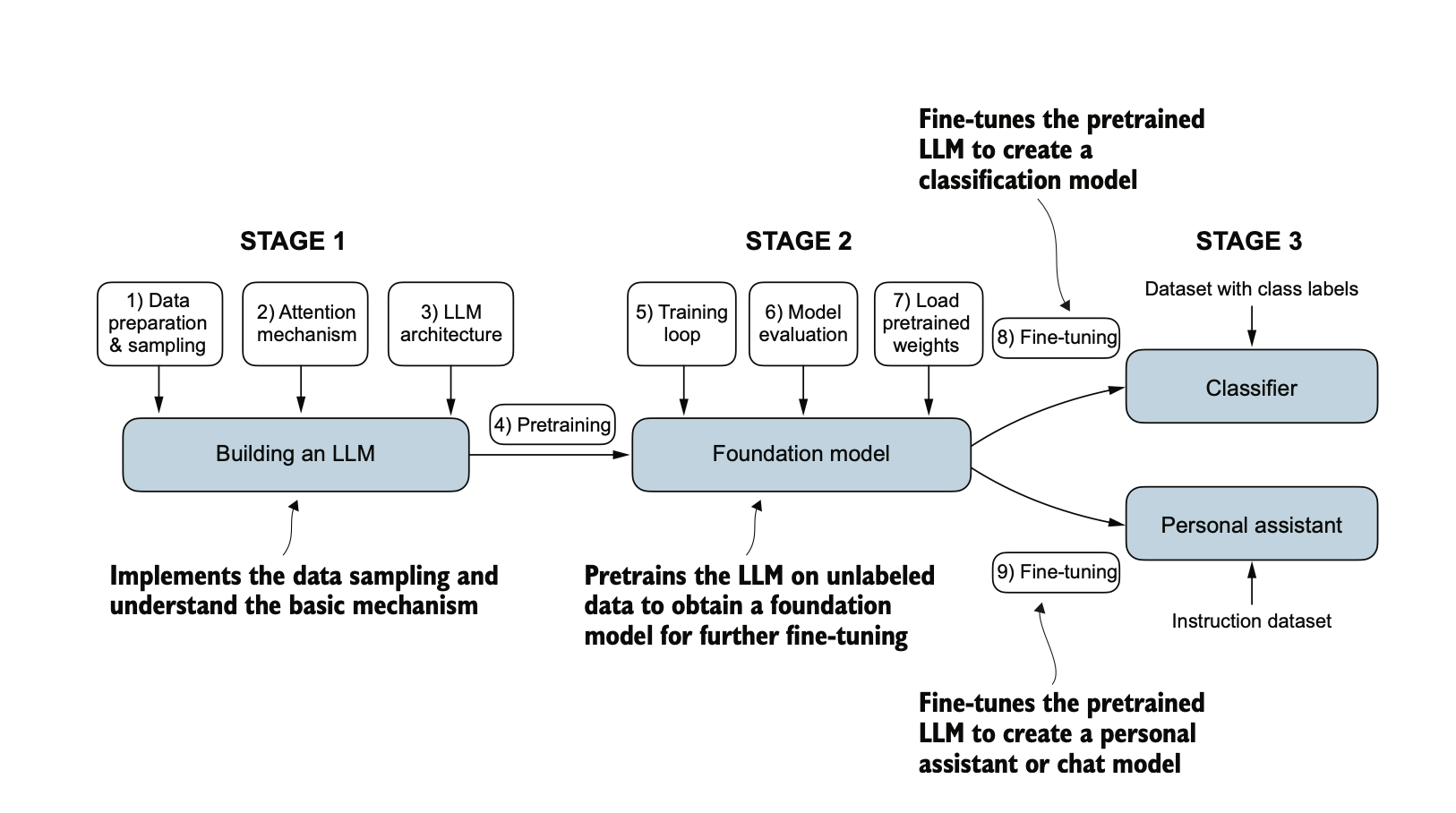
Figure 1: The three-stage process of building and training Large Language Models.
Stage 1: Building the LLM (Data + Architecture)
Every LLM begins with three critical components:
- Data preparation & sampling – breaking down massive amounts of text into tokens the model can process.
- Attention mechanism – the core idea behind transformers, allowing the model to “pay attention” to the most relevant words in a sequence.
- LLM architecture – the actual neural network structure, usually based on the GPT-style transformer decoder.
This stage is about implementation: coding the attention mechanism, designing the model layers, and setting up the data pipeline. The result is not yet a useful AI assistant—it’s just the skeleton of an LLM, ready to be trained.
Stage 2: Pretraining – Building a Foundation Model
Next comes pretraining, which is like giving the model the biggest library in the world.
The model is fed trillions of words of unlabeled text (books, articles, websites, research papers). Its simple task is, predict the next word in a sentence.
Example: given "Peanut butter and ___", the model learns to predict "jelly."
This is self-supervised learning—the labels come from the data itself. Through countless predictions, the LLM begins to capture:
- Grammar and sentence structure
- Factual knowledge
- Contextual patterns
- Basic reasoning skills
And here’s the surprising part: even though the task is simple, scaling it up leads to emergent abilities. Models trained only on next-word prediction have demonstrated unexpected skills like translation, summarization, and reasoning—capabilities never explicitly programmed.
Key components in this stage include:
- Training loop – iteratively updating weights through backpropagation.
- Model evaluation – checking how well the model predicts new text during training.
- Pretrained weights – saving and reloading learned parameters for reuse.
The result is a foundation model: a reusable base model with broad knowledge, but no specialization yet.
Stage 3: Finetuning – Specializing the Foundation Model
If pretraining is like college, finetuning is job training.
We take the foundation model and adapt it for a specific task using smaller, labeled datasets.
There are two common finetuning pathways:
1. Fine-tuning for Classification
- Dataset: inputs + class labels (e.g., spam vs. not spam).
- Output: a classifier that can categorize new text.
2. Fine-tuning for Instruction Following
- Dataset: instruction–response pairs (e.g., “Translate to French → Bonjour”).
- Output: a personal assistant / chat model that can follow instructions.
This distinction is critical: classification finetuning produces narrow tools, while instruction finetuning creates assistants like ChatGPT that can handle open-ended prompts.
This step is also far more efficient than pretraining. Instead of starting from scratch, we reuse pretrained weights and adapt them. In practice, companies often use techniques like parameter-efficient finetuning (e.g., LoRA) to reduce cost even further.
Where Does Evaluation Fit In?
You might wonder: what about evaluation?
Evaluation isn’t its own stage but is woven throughout Stage 2 and Stage 3:
- During pretraining, we evaluate with loss and perplexity (a measure of how well the model predicts sequences).
- During finetuning, we evaluate task-specific metrics such as:
- Accuracy (classification tasks)
- BLEU scores (translation tasks)
- Human preference ratings (instruction-following models)
This “final exam” ensures the model is reliable before being deployed.
References
- Sebastian Raschka. Build a Large Language Model (From Scratch). Manning Publications, 2025.